从算力到智能:强化学习驱动的去中心化AI投资地图
作者:Jacob Zhao @IOSG
人工智能正从以“模式拟合”为主的统计学习,迈向以“结构化推理”为核心的能力体系,后训练(Post-training)的重要性快速上升。DeepSeek-R1 的出现标志着强化学习在大模型时代的范式级翻身,行业共识形成:预训练构建模型的通用能力基座,强化学习不再只是价值对齐工具,而被证明能够系统提升推理链质量与复杂决策能力,正逐步演化为持续提升智能水平的技术路径。
与此同时,Web3 正通过去中心化算力网络与加密激励体系重构 AI 的生产关系,而强化学习对 rollout 采样、奖励信号与可验证训练的结构性需求,恰与区块链的算力协作、激励分配与可验证执行天然契合。本研报将系统拆解 AI 训练范式与强化学习技术原理,论证强化学习 × Web3 的结构优势,并对 Prime Intellect、Gensyn、Nous Research、Gradient、Grail 和 Fraction AI 等项目进行分析。
AI 训练的三阶段:预训练、指令微调与后训练对齐
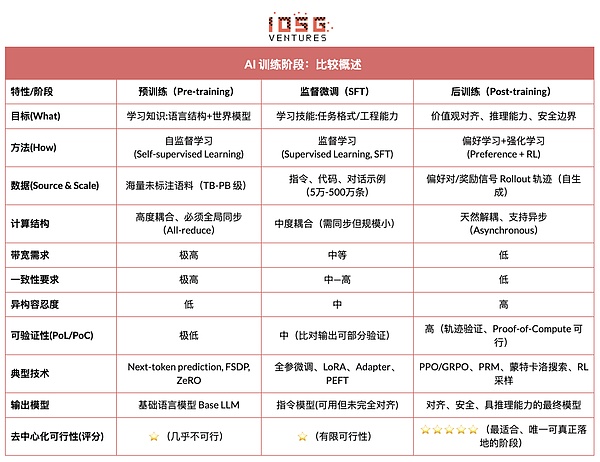
现代大语言模型(LLM)训练全生命周期通常被划分为三个核心阶段:预训练(Pre-training)、监督微调(SFT)和后训练(Post-training/RL)。三者分别承担“构建世界模型—注入任务能力—塑造推理与价值观”的功能,其计算结构、数据要求与验证难度决定了去中心化的匹配程度。
-
预训练(Pre-training)通过大规模自监督学习(Self-supervised Learning)构建模型的语言统计结构与跨模态世界模型,是 LLM 能力的根基。此阶段需在万亿级语料上以全局同步方式训练,依赖数千至数万张 H100 的同构集群,成本占比高达 80–95%,对带宽与数据版权极度敏感,因此必须在高度集中式环境中完成。
-
微调(Supervised Fine-tuning)用于注入任务能力与指令格式,数据量小、成本占比约 5–15%,微调既可以进行全参训练,也可以采用参数高效微调(PEFT)方法,其中 LoRA、Q-LoRA 与 Adapter 是工业界主流。但仍需同步梯度,使其去中心化潜力有限。
-
后训练(Post-training)由多个迭代子阶段构成,决定模型的推理能力、价值观与安全边界,其方法既包括强化学习体系(RLHF、RLAIF、GRPO)也包括无 RL 的偏好优化方法(DPO),以及过程奖励模型(PRM)等。该阶段数据量与成本较低(5–10%),主要集中在 Rollout 与策略更新;其天然支持异步与分布式执行,节点无需持有完整权重,结合可验证计算与链上激励可形成开放的去中心化训练网络,是最适配 Web3 的训练环节。
强化学习技术全景:架构、框架与应用
强化学习的系统架构与核心环节
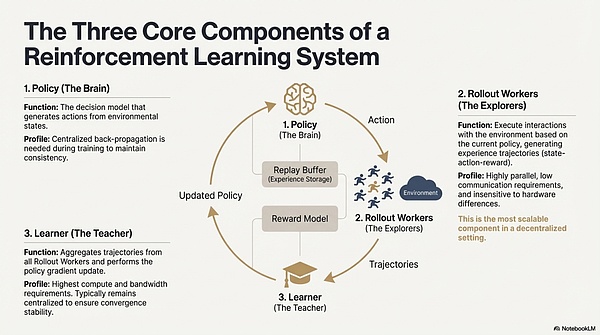
强化学习(Reinforcement Learning, RL)通过“环境交互—奖励反馈—策略更新”驱动模型自主改进决策能力,其核心结构可视为由状态、动作、奖励与策略构成的反馈闭环。一个完整的 RL 系统通常包含三类组件:Policy(策略网络)、Rollout(经验采样)与 Learner(策略更新器)。策略与环境交互生成轨迹,Learner 根据奖励信号更新策略,从而形成持续迭代、不断优化的学习过程:
-
策略网络(Policy):从环境状态生成动作,是系统的决策核心。训练时需集中式反向传播维持一致性;推理时可分发至不同节点并行运行。
-
经验采样(Rollout):节点根据策略执行环境交互,生成状态—动作—奖励等轨迹。该过程高度并行、通信极低,对硬件差异不敏感是最适合在去中心化中扩展的环节。
-
学习器(Learner):聚合全部 Rollout 轨迹并执行策略梯度更新,是唯一对算力、带宽要求最高的模块,因此通常保持中心化或轻中心化部署以确保收敛稳定性。
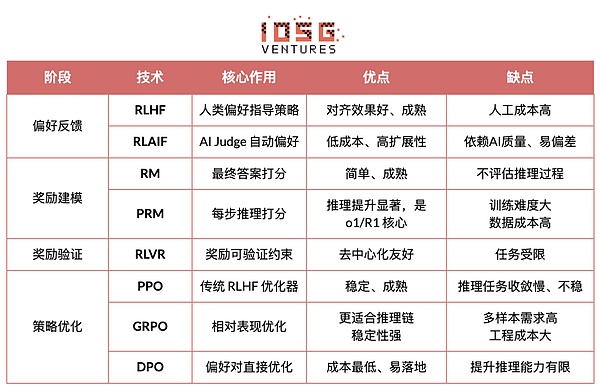
强化学习阶段框架(RLHF → RLAIF → PRM → GRPO)
强化学习通常可分为五个阶段,整体流程如下所述:
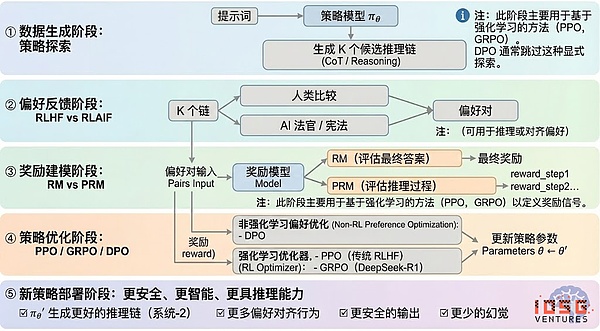
#数据生成阶段(Policy Exploration)
在给定输入提示的条件下,策略模型 πθ 生成多条候选推理链或完整轨迹,为后续偏好评估与奖励建模提供样本基础,决定了策略探索的广度。
#偏好反馈阶段(RLHF / RLAIF)
-
RLHF(Reinforcement Learning from Human Feedback)通过多候选回答、人工偏好标注、训练奖励模型(RM)并用 PPO 优化策略,使模型输出更符合人类价值观,是 GPT-3.5 → GPT-4 的关键一环
-
RLAIF(Reinforcement Learning from AI Feedback)以 AI Judge 或宪法式规则替代人工标注,实现偏好获取自动化,显著降低成本并具备规模化特性,已成为 Anthropic、OpenAI、DeepSeek 等的主流对齐范式。
#奖励建模阶段(Reward Modeling)
偏好对输入奖励模型,学习将输出映射为奖励。RM 教模型“什么是正确答案”,PRM 教模型“如何进行正确推理”。
-
RM(Reward Model)用于评估最终答案的好坏,仅对输出打分:
-
过程奖励模型PRM(Process Reward Model)它不再只评估最终答案,而是为每一步推理、每个 token、每个逻辑段打分,也是 OpenAI o1 与 DeepSeek-R1 的关键技术,本质上是在“教模型如何思考”。
#奖励验证阶段(RLVR / Reward Verifiability)
在奖励信号生成与使用过程中引入“可验证约束”,使奖励尽可能来自可复现的规则、事实或共识,从而降低 reward hacking 与偏差风险,并提升在开放环境中的可审计性与可扩展性。
#策略优化阶段(Policy Optimization)
是在奖励模型给出的信号指导下更新策略参数 θ,以得到更强推理能力、更高安全性与更稳定行为模式的策略 πθ′。主流优化方式包括:
-
PPO(Proximal Policy Optimization): RLHF 的传统优化器,以稳定性见长,但在复杂推理任务中往往面临收敛慢、稳定性不足等局限。
-
GRPO(Group Relative Policy Optimization):是 DeepSeek-R1 的核心创新,通过对候选答案组内优势分布进行建模以估计期望价值,而非简单排序。该方法保留了奖励幅度信息,更适合推理链优化,训练过程更稳定,被视为继 PPO 之后面向深度推理场景的重要强化学习优化框架。
-
DPO(Direct Preference Optimization):非强化学习的后训练方法:不生成轨迹、不建奖励模型,而是直接在偏好对上做优化,成本低、效果稳定,因而被广泛用于 Llama、Gemma 等开源模型的对齐,但不提升推理能力。
#新策略部署阶段(New Policy Deployment)
经过优化后的模型表现为:更强的推理链生成能力(System-2 Reasoning)、更符合人类或 AI 偏好的行为、更低的幻觉率、更高的安全性。模型在持续迭代中不断学习偏好、优化过程、提升决策质量,形成闭环。
强化学习的产业应用五大分类
强化学习(Reinforcement Learning)已从早期的博弈智能演进为跨产业的自主决策核心框架,其应用场景按照技术成熟度与产业落地程度,可归纳为五大类别,并在各自方向推动了关键突破。
-
博弈与策略系统(Game & Strategy):是 RL 最早被验证的方向,在 AlphaGo、AlphaZero、AlphaStar、OpenAI Five 等“完美信息 + 明确奖励”的环境中,RL 展示了可与人类专家比肩甚至超越的决策智能,为现代 RL 算法奠定基础。
-
机器人与具身智能(Embodied AI):RL 通过连续控制、动力学建模与环境交互,使机器人学习操控、运动控制和跨模态任务(如 RT-2、RT-X),正快速迈向产业化,是现实世界机器人落地的关键技术路线。
-
数字推理(Digital Reasoning / LLM System-2):RL + PRM 推动大模型从“语言模仿”走向“结构化推理”,代表成果包括 DeepSeek-R1、OpenAI o1/o3、Anthropic Claude 及 AlphaGeometry,其本质是在推理链层面进行奖励优化,而非仅评估最终答案。
-
自动化科学发现与数学优化(Scientific Discovery):RL 在无标签、复杂奖励与巨大搜索空间中寻找最优结构或策略,已实现 AlphaTensor、AlphaDev、Fusion RL 等基础突破,展现出超越人类直觉的探索能力。
-
经济决策与交易系统(Economic Decision-making & Trading):RL 被用于策略优化、高维风险控制与自适应交易系统生成,相较传统量化模型更能在不确定环境中持续学习,是智能金融的重要构成部分。
强化学习与 Web3 的天然匹配
强化学习(RL)与 Web3 的高度契合,源于二者本质上都是“激励驱动系统”。RL 依赖奖励信号优化策略,区块链依靠经济激励协调参与者行为,使两者在机制层面天然一致。RL 的核心需求——大规模异构 Rollout、奖励分配与真实性验证——正是 Web3 的结构优势所在。
#推理与训练解耦
强化学习的训练过程可明确拆分为两个阶段:
-
Rollout (探索采样):模型基于当前策略生成大量数据,计算密集型但通信稀疏型的任务。它不需要节点间频繁通信,适合在全球分布的消费级 GPU 上并行生成。
-
Update (参数更新):基于收集到的数据更新模型权重,需高带宽中心化节点完成。
“推理—训练解耦”天然契合去中心化的异构算力结构:Rollout 可外包给开放网络,通过代币机制按贡献结算,而模型更新保持集中化以确保稳定性。
#可验证性 (Verifiability)
ZK 与 Proof-of-Learning 提供了验证节点是否真实执行推理的手段,解决了开放网络中的诚实性问题。在代码、数学推理等确定性任务中,验证者只需检查答案即可确认工作量,大幅提升去中心化 RL 系统的可信度。
#激励层,基于代币经济的反馈生产机制
Web3 的代币机制可直接奖励 RLHF/RLAIF 的偏好反馈贡献者,使偏好数据生成具备透明、可结算、无需许可的激励结构;质押与削减(Staking/Slashing)进一步约束反馈质量,形成比传统众包更高效且对齐的反馈市场。
#多智能体强化学习(MARL)潜力
区块链本质上是公开、透明、持续演化的多智能体环境,账户、合约与智能体不断在激励驱动下调整策略,使其天然具备构建大规模 MARL 实验场的潜力。尽管仍在早期,但其状态公开、执行可验证、激励可编程的特性,为未来 MARL 的发展提供了原则性优势。
经典 Web3 + 强化学习项目解析
基于上述理论框架,我们将对当前生态中最具代表性的项目进行简要分析:
Prime Intellect: 异步强化学习范式 prime-rl
Prime Intellect 致力于构建全球开放算力市场,降低训练门槛、推动协作式去中心化训练,并发展完整的开源超级智能技术栈。其体系包括:Prime Compute(统一云/分布式算力环境)、INTELLECT 模型家族(10B–100B+)、开放强化学习环境中心(Environments Hub)、以及大规模合成数据引擎(SYNTHETIC-1/2)。
Prime Intellect 核心基础设施组件 prime-rl 框架专为异步分布式环境设计与强化学习高度相关,其余包括突破带宽瓶颈的 OpenDiLoCo 通信协议、保障计算完整性的 TopLoc 验证机制等。
#Prime Intellect 核心基础设施组件一览
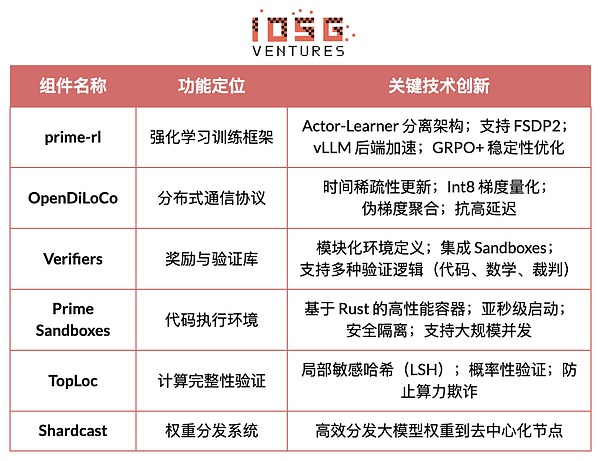
#技术基石:prime-rl 异步强化学习框架
prime-rl 是 Prime Intellect 的核心训练引擎,专为大规模异步去中心化环境设计,通过 Actor–Learner 完全解耦实现高吞吐推理与稳定更新。执行者 (Rollout Worker) 与学习者(Trainer) 不再同步阻塞,节点可随时加入或退出,只需持续拉取最新策略并上传生成数据即可:
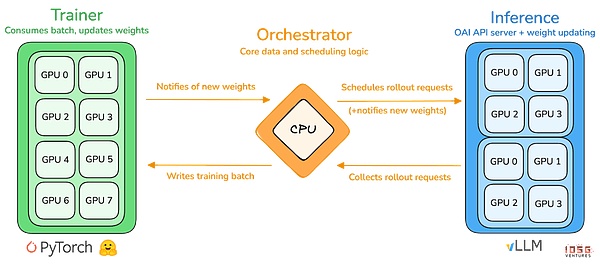
-
执行者 Actor (Rollout Workers):负责模型推理和数据生成。Prime Intellect 创新性地在 Actor 端集成了 vLLM 推理引擎 。vLLM 的 PagedAttention 技术和连续批处理(Continuous Batching)能力,使得 Actor 能够以极高的吞吐量生成推理轨迹。
-
学习者 Learner (Trainer):负责策略优化。Learner 从共享的经验回放缓冲区(Experience Buffer)中异步拉取数据进行梯度更新,无需等待所有 Actor 完成当前批次。
-
协调器 (Orchestrator):负责调度模型权重与数据流。
#prime-rl 的关键创新点
-
完全异步(True Asynchrony):prime-rl 摒弃传统 PPO 的同步范式,不等待慢节点、无需批次对齐,使任意数量与性能的 GPU 都能随时接入,奠定去中心化 RL 的可行性。
-
深度集成 FSDP2 与 MoE:通过 FSDP2 参数切片与 MoE 稀疏激活,prime-rl 让百亿级模型在分布式环境中高效训练,Actor 仅运行活跃专家,大幅降低显存与推理成本。
-
GRPO+(Group Relative Policy Optimization):GRPO 免除 Critic 网络,显著减少计算与显存开销,天然适配异步环境,prime-rl 的 GRPO+ 更通过稳定化机制确保高延迟条件下的可靠收敛。
#INTELLECT 模型家族:去中心化 RL 技术成熟度的标志
-
INTELLECT-1(10B,2024年10月)首次证明 OpenDiLoCo 能在跨三大洲的异构网络中高效训练(通信占比 <2%、算力利用率 98%),打破跨地域训练的物理认知;
-
INTELLECT-2(32B,2025年4月)作为首个 Permissionless RL 模型,验证 prime-rl 与 GRPO+ 在多步延迟、异步环境中的稳定收敛能力,实现全球开放算力参与的去中心化 RL;
-
INTELLECT-3(106B MoE,2025年11月)采用仅激活 12B 参数的稀疏架构,在 512×H200 上训练并实现旗舰级推理性能(AIME 90.8%、GPQA 74.4%、MMLU-Pro 81.9% 等),整体表现已逼近甚至超越规模远大于自身的中心化闭源模型。
Prime Intellect 此外还构建了数个支撑性基础设施:OpenDiLoCo 通过时间稀疏通信与量化权重差,将跨地域训练的通信量降低数百倍,使 INTELLECT-1 在跨三洲网络仍保持 98% 利用率;TopLoc + Verifiers 形成去中心化可信执行层,以激活指纹与沙箱验证确保推理与奖励数据的真实性;SYNTHETIC 数据引擎则生产大规模高质量推理链,并通过流水线并行让 671B 模型在消费级 GPU 集群上高效运行。这些组件为去中心化 RL 的数据生成、验证与推理吞吐提供了关键的工程底座。INTELLECT 系列证明了这一技术栈可产生成熟的世界级模型,标志着去中心化训练体系从概念阶段进入实用阶段。
Gensyn: 强化学习核心栈RL Swarm与SAPO
Gensyn 的目标是将全球闲置算力汇聚成一个开放、无需信任、可无限扩展的 AI 训练基础设施。其核心包括跨设备标准化执行层、点对点协调网络与无需信任的任务验证系统,并通过智能合约自动分配任务与奖励。围绕强化学习的特点,Gensyn 引入 RL Swarm、SAPO 与 SkipPipe 等核心机制等机制,将生成、评估、更新三个环节解耦,利用全球异构 GPU 组成的“蜂群”实现集体进化。其最终交付的不是单纯的算力,而是可验证的智能(Verifiable Intelligence)。
#Gensyn 堆栈的强化学习应用
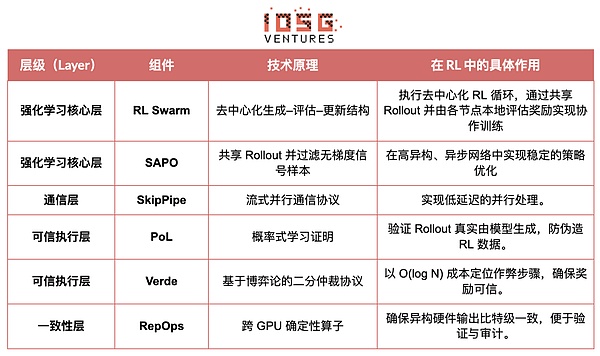
#RL Swarm:去中心化的协作式强化学习引擎
RL Swarm 展示了一种全新的协作模式。它不再是简单的任务分发,而是一个模拟人类社会学习
免责声明:
1.资讯内容不构成投资建议,投资者应独立决策并自行承担风险
2.本文版权归属原作所有,仅代表作者本人观点,不代币币情的观点或立场
 首页
首页 快讯
快讯